 de.uni_leipzig.cvk.data.cluster.ClusterAlgorithm
de.uni_leipzig.cvk.data.cluster.ClusterAlgorithm
|
|||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||||
java.lang.Object
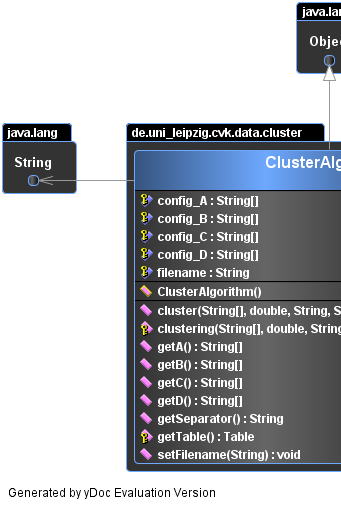
public abstract class ClusterAlgorithm
Is an abstract base class for a concrete cluster algorithm implementation.
A concrete algorithm just need to implement the clustering(String[], double, String, String, String, String) method.
The four String parameters comes from the member String arrays config_A ,..., config_D
and can be used for different configurations of an algorithm by overriding this members,
e.g. use config_A = new String[]{"k","1",...,"100"} for parameter k of k-nearest neighbours algorithm.
The first element in an array is a value for a JLabel which describes the configuration for the user.
A user can choose the other elements of each array from a JComboBox in the application and
this values will sent back to the clustering method as parameters so that they can be used for configurations.
The String filename member variable contains the path to a delimiter separated text file,
separators are space, comma or tabulator. See getSeparator().
After a new algorithm has been implemented, it still needs to be added to the application.
For this use the ClusterContext class with the
ClusterContext.addAlgorithm(String, ClusterAlgorithm) method.
For example, write in Main.clusterVisualizationKitDemo() method (which starts the application) the following:
Model model = new Model();
ClusterContext cc = model.getClusterContext();
cc.addAlgorithm("Foobar", new ClusterAlgorithmFoobar());
ClusterContext.ClusterContext() constructor to append the algorithm.
 |
 |
| Field Summary | |
|---|---|
protected java.lang.String[] |
config_A
An array of default available settings, override this array for a concrete configuration. |
protected java.lang.String[] |
config_B
An array of default available settings, override this array for a concrete configuration. |
protected java.lang.String[] |
config_C
An array of default available settings, override this array for a concrete configuration. |
protected java.lang.String[] |
config_D
An array of default available settings, override this array for a concrete configuration. |
protected java.lang.String |
filename
path to file |
| Fields inherited from interface de.uni_leipzig.cvk.data.cluster.ClusterTableSettings |
|---|
CLUSTER_COLUMN_ID, CLUSTER_COLUMN_ID_TYPE, CLUSTER_COLUMN_NAME, CLUSTER_COLUMN_NAME_TYPE, CLUSTER_COLUMN_SIZE, CLUSTER_COLUMN_SIZE_TYPE |
| Constructor Summary | |
|---|---|
ClusterAlgorithm()
|
|
| Method Summary | |
|---|---|
prefuse.data.Table |
cluster(java.lang.String[] seeds,
double threshold,
java.lang.String values_A,
java.lang.String values_B,
java.lang.String values_C,
java.lang.String values_D)
A template method to call the concrete clustering method. |
protected abstract prefuse.data.Table |
clustering(java.lang.String[] seeds,
double threshold,
java.lang.String values_A,
java.lang.String values_B,
java.lang.String values_C,
java.lang.String values_D)
An abstract method for a concrete clustering algorithm implementation or adaption. |
java.lang.String[] |
getA()
gets available configuration |
java.lang.String[] |
getB()
gets available configuration |
java.lang.String[] |
getC()
gets available configuration |
java.lang.String[] |
getD()
gets available configuration |
java.lang.String |
getSeparator()
gets the separator of filename depends on the file extension |
protected prefuse.data.Table |
getTable()
gets a valid Table, that means
with a column of ClusterTableSettings.CLUSTER_COLUMN_NAME
and a type of ClusterTableSettings.CLUSTER_COLUMN_NAME_TYPE
for the cluster data |
void |
setFilename(java.lang.String name)
sets filename, the path to file |
| Methods inherited from class java.lang.Object |
|---|
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait |
| Field Detail |
|---|
protected java.lang.String[] config_A
clustering(String[], double, String, String, String, String).
protected java.lang.String[] config_B
clustering(String[], double, String, String, String, String).
protected java.lang.String[] config_C
clustering(String[], double, String, String, String, String).
protected java.lang.String[] config_D
clustering(String[], double, String, String, String, String).
protected java.lang.String filename
| Constructor Detail |
|---|
public ClusterAlgorithm()
| Method Detail |
|---|
public final prefuse.data.Table cluster(java.lang.String[] seeds,
double threshold,
java.lang.String values_A,
java.lang.String values_B,
java.lang.String values_C,
java.lang.String values_D)
ClusterTableSettings.CLUSTER_COLUMN_NAME and ClusterTableSettings.CLUSTER_COLUMN_NAME_TYPE)
Sorts clusterTable parameter with the column ClusterTableSettings.CLUSTER_COLUMN_SIZE.
seeds - all selected seedsthreshold - threshold is between 0 and 1 or -1 for all nodesvalues_A - value of config_A arrayvalues_B - value of config_B arrayvalues_C - value of config_C arrayvalues_D - value of config_D array
protected abstract prefuse.data.Table clustering(java.lang.String[] seeds,
double threshold,
java.lang.String values_A,
java.lang.String values_B,
java.lang.String values_C,
java.lang.String values_D)
ClusterTableSettings.CLUSTER_COLUMN_NAME and with a column type of ClusterTableSettings.CLUSTER_COLUMN_NAME_TYPE.
The column ClusterTableSettings.CLUSTER_COLUMN_SIZE is reserved for a inner sort operation, you don't have to use it, but you can
use this column to add the size of a cluster with type of ClusterTableSettings.CLUSTER_COLUMN_SIZE_TYPE, but be sure that every row is set with a value.
This size defines the order of printing the clusters, the highest value of size for a cluster will print first.
seeds - selected nodes that will be used as seedsthreshold - threshold is between 0 and 1 or -1 for all nodesvalues_A - value of config_A arrayvalues_B - value of config_B arrayvalues_C - value of config_C arrayvalues_D - value of config_D array
public java.lang.String[] getA()
public java.lang.String[] getB()
public java.lang.String[] getC()
public java.lang.String[] getD()
public java.lang.String getSeparator()
filename depends on the file extension
protected prefuse.data.Table getTable()
Table, that means
with a column of ClusterTableSettings.CLUSTER_COLUMN_NAME
and a type of ClusterTableSettings.CLUSTER_COLUMN_NAME_TYPE
for the cluster data
public void setFilename(java.lang.String name)
filename, the path to file
|
|||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||||